欢迎参与讨论,转载请注明出处。
前言
SPK文件是DNF的一种更新时所用的压缩包(国服除外),在更新时会从服务器下载这种SPK文件然后于本地解压。有时候为了获得更快的速度,以及突破墙的限制,我们通过获取到更新服务器的网址直接下载。但是此刻对于如何将SPK文件解压便是个问题了,本文遂由此而生。
详解
SPK文件的本质上是将原文件按照一定规则进行分割成多个片段,然后对这些片段使用bzip2算法进行压缩。以下是文件结构图: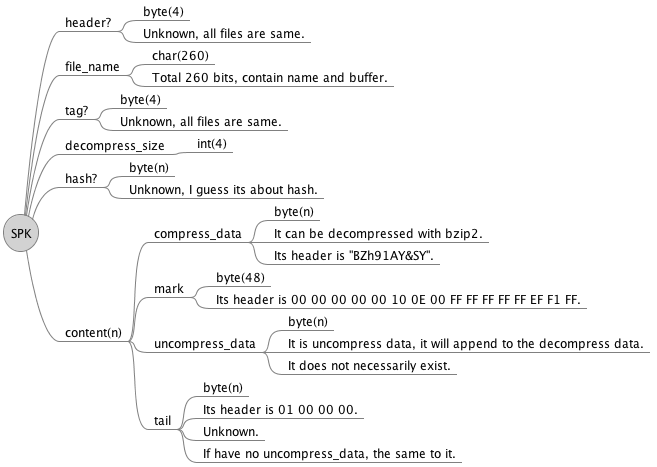
由于信息的不对称,导致不少地方是处于盲区的,不过这并不影响获取到关键数据。这种被压缩的片段开头标识为”BZh91AY&SY”,所以只需要以此为关键字进行分割就能得出关键数据了,不过实际操作时发现除了压缩数据之外还有非压缩数据,并且会用一段48字节的数据进行分隔。且拥有非压缩数据的片段结尾也会有一段意味不明的数据,好在它们都有对应的开头标识,进行分割即可。
在得出压缩数据后使用bzip2算法进行解压缩,然后将所有解压后的数据与非压缩数据按顺序进行拼接,每个片段如此类推最后总体拼接起来即可得到完整的原文件。本次解析使用的环境是Python3.6,以下是过程代码:
|
|
后记
事实上这种SPK的压缩机制效果根本是微乎其微,我完全不明白Neople这么做的用意。以及片段的划分机制和诸多盲区都没搞懂,看来我得考虑学下逆向方面的知识了。不过无论如何,最终要达到的目标还是做到了。