欢迎参与讨论,转载请注明出处。
前言
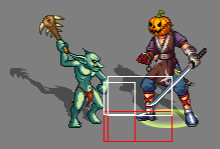
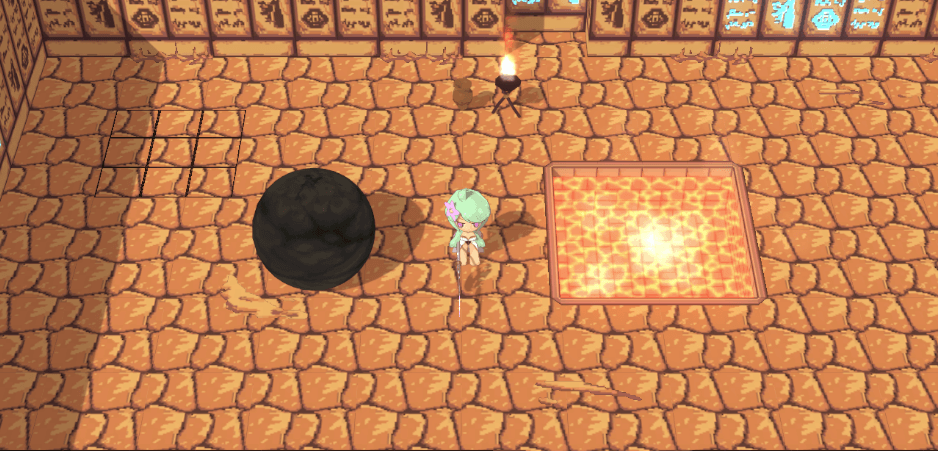
最近在Demo开发的过程中,遇到了一个细节问题,场景模型之间的边界感很弱:
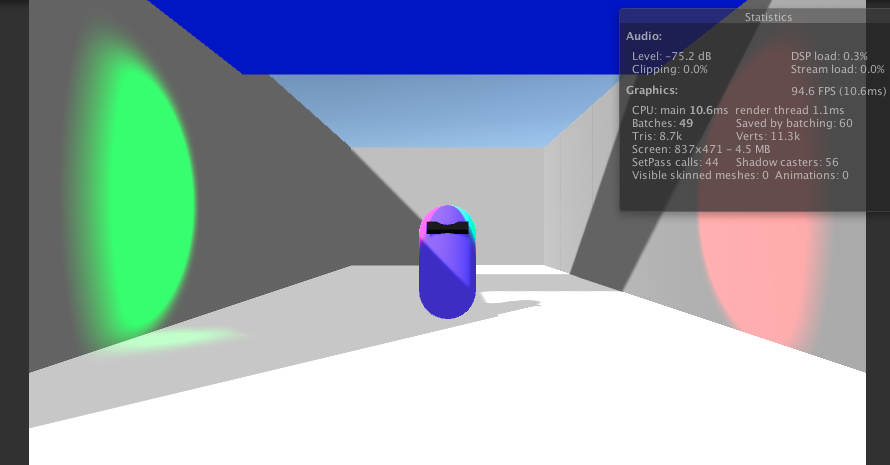
这样就会导致玩家难以分辨接下来面对的究竟是可以跳下去的台阶,亦或是要跳过去的台阶了。我们想到的解决方法便是给场景模型加个外描边,以此区分:
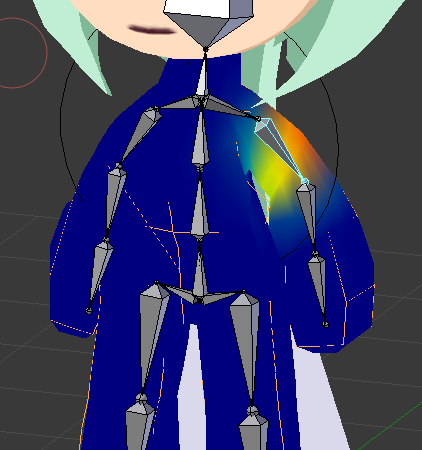
整挺好,于是本文就来介绍一下实现思路。首先按照惯性我们直接采用了与人物相同的法线外扩描边,但是效果却不尽人意:
这完全就牛头不对马嘴,既然老办法不好使那就看看后处理描边吧。不过由于Demo使用的渲染管线是URP,在后处理这块与原生完全不同。于是乎再一次踏上了踩坑之旅……
另附源码地址:https://github.com/MusouCrow/TypeOutline
RenderFeature
经过调查发现,URP除了Post-processing之外,并没有直接提供屏幕后处理的方案。而URP的Post-processing尚不稳定(与原生产生了版本分裂),所以还是去寻找更稳妥的方式。根据官方例程找到了实现屏幕后处理描边的方式,当然它们的描边实现方式很搓,并不适合我们项目。于是取其精华去其糟粕,发现了其实现后处理的关键:RenderFeature。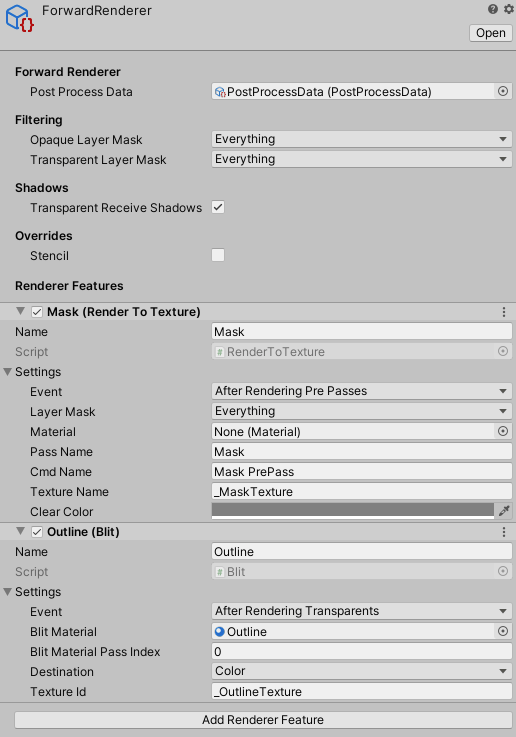
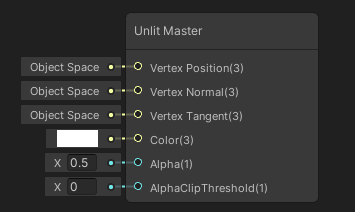
RenderFeature系属于URP的配置三件套之一的Forward Renderer,你可以在该配置文件里添加想要的RenderFeature,可以将它看做是一种自定义的渲染行为,通过CommandBuffer提交自己的渲染命令到任一渲染时点(如渲染不透明物体后、进行后处理之前)。URP默认只提供了RenderObjects这一RenderFeature,作用是使用特定的材质,在某个渲染时机,对某些Layer的对象进行一遍渲染。这显然不是我们所需要的,所幸官方例程里提供了我们想要的RenderFeature——Blit,它提供了根据材质、且材质可获取屏幕贴图,并渲染到屏幕上的功能:
|
|

如此这般便实现了经典的反色效果,只要引入Blit的相关代码,然后在Forward Renderer文件进行RenderFeature的相关配置,并实现Shader与材质,即可生效。较之原生在MonoBehaviour做这种事,URP的设计明显更为合理。
Outline
后处理部署完毕,接下来便是描边的实现了。按照正统的屏幕后处理做法,应该是基于一些屏幕贴图(深度、法线、颜色等),使用Sobel算子之类做边缘检测。然而也有一些杂技做法,如官方例程以及此篇。当然相同的是,它们都需要使用屏幕贴图作为依据来进行处理,不同的屏幕贴图会导致不一样的效果,如上文那篇就使用深度与法线结合的贴图,产生了内描边的效果。然而我们只需要外描边而已,所以使用深度贴图即可。
深度贴图在URP的获取相当简单,只需要在RenderPipelineAsset文件将Depth Texture勾选,然后便可在后处理Shader通过_CameraDepthTexture变量获取: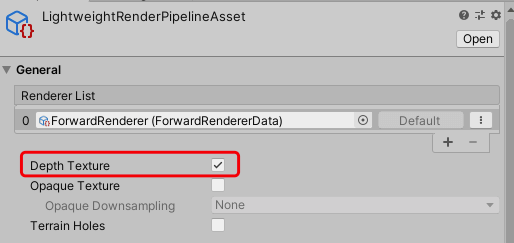
有了深度贴图,那么接下来逮着别人的Shader抄就完事了——然而那些杂技做法的效果通通不行:官方的更适合美式风格,上文那篇的做法在某些场合会产生奇怪的斑点。于是只好按照《UnityShader入门精要》的写法来了:
|
|

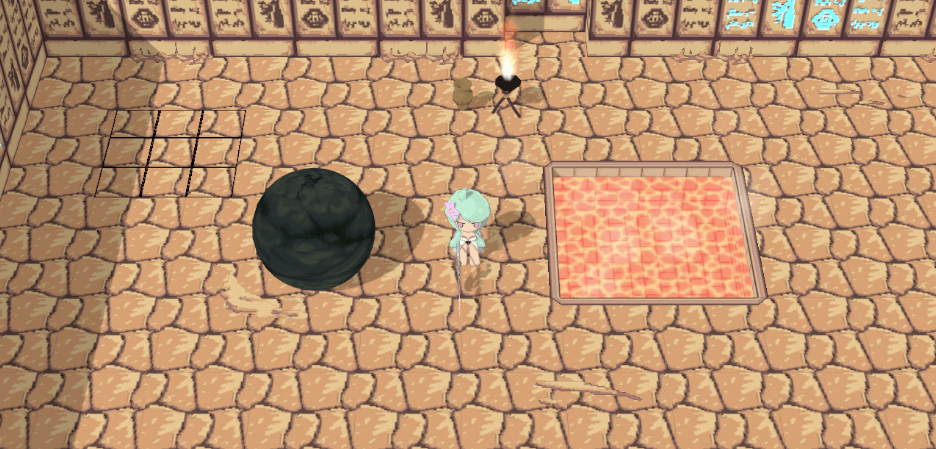
很棒,但是可以看到,身为一般物件的方砖也被描边了,可我们想要的只是场景描边而已——于是进入了最后的难题:对特定对象的后处理。
Mask
首先我们参考原生下的做法,利用模板测试的特性,对特定对象的Shader写入模板值,然后在后处理时根据模板值做判断是否处理,确实是个绝妙的做法——很可惜,在URP下我找不到能够生效的做法。根据上文那篇需要渲染出深度法线结合的屏幕贴图的需要,作者实现了一个新的RenderFeature:根据渲染对象们的某个Pass,渲染成一张新的屏幕贴图(可选择使用特定的材质,若不使用则是Pass的结果)。并可作为全局变量供后续的后处理Shader使用。我将之命名为RenderToTexture,这也是后处理常用的一种技术。
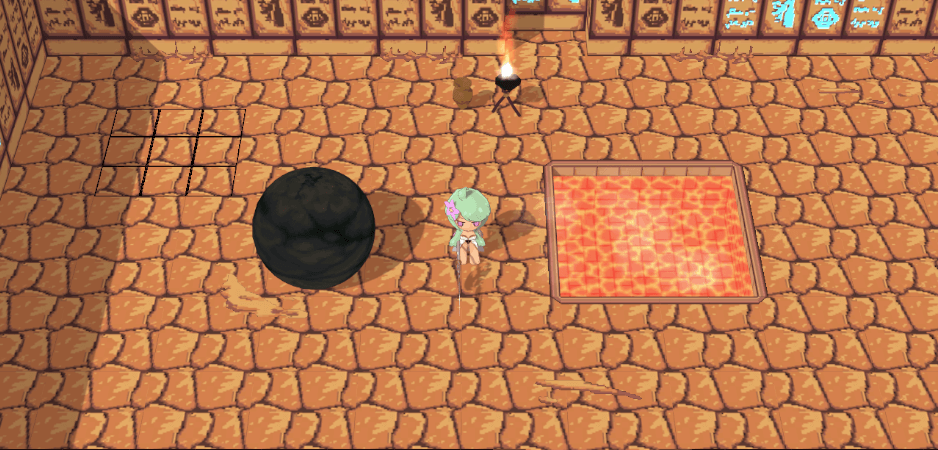
有了这个便有了新的想法:为所有渲染对象的Shader添加新的Pass(名为Mask),该Pass根据参数配置决定渲染成怎样的颜色(需要描边为白色,不需要为黑色)。如此渲染成屏幕贴图后便可作为描边Shader的参考(下称Mask贴图),决定是否需要描边: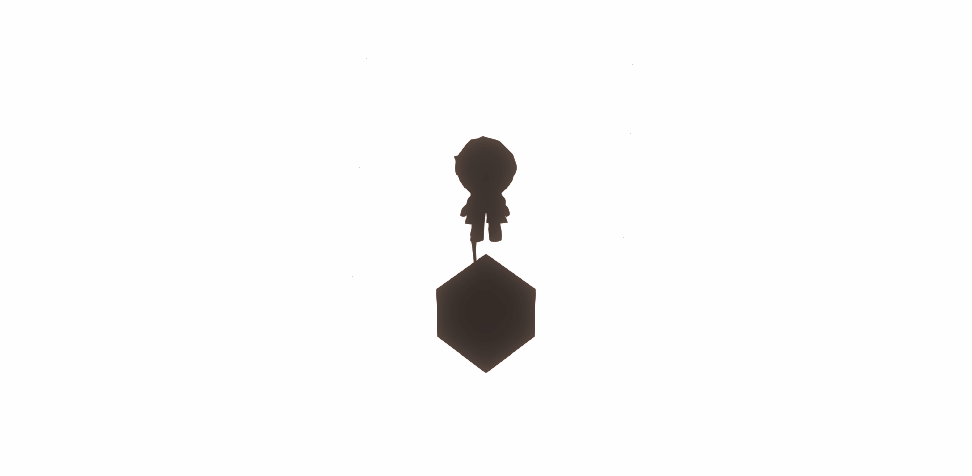
注意要为Mask贴图的底色设置为非黑色,否则与底色接壤的物件会描边失败。那么见证成果吧:
|
|

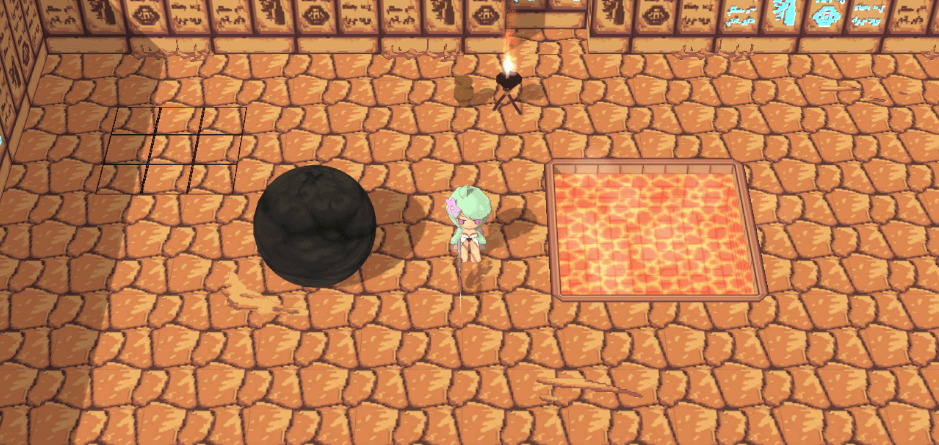
很棒,这下一般物件不会被描边了,局部后处理描边完成!当然随后遇到一个新的问题:
这是因为透明(Transparent)模式下的对象按照通用做法是不会写入深度信息的(为了透明时能看到模型内部),然而我们描边需要的正是深度信息,由于树叶没有写入深度信息,所以在描边时当它不存在了,于是产生了这样的结果。解决方法也好办,在透明模式也写入深度信息(ZWrite)即可,毕竟我们的透明模型不需要看到内部,一举两得。
后记
其实期间还产生了投机心理,想着把角色自带的描边给废了,统一后处理,岂不美哉?很可惜搞出来的效果始终是不满意,法线外扩 is Good,没办法喽——
顺带一提,对于后处理的贴图创建记得将msaaSamples属性设为1,否则就会进行抗锯齿处理,那可真的炸裂……




























 Subtractive: 全烘焙
Subtractive: 全烘焙 Shadowmask: 烘焙阴影与间接光
Shadowmask: 烘焙阴影与间接光 Backed Indirect: 只烘焙间接光
Backed Indirect: 只烘焙间接光